Ceph - a long debug

Hello again! Yet a longer time between posts, but at least my colleagues on https://pouta.blog.csc.fi are holding the fort!
Generic disclaimer: Ceph Hammer/Jewel, CentOS7
Most of the work was done by our Ceph team, yours truly was partially involved.
Background
We've been using Ceph for a long time, and it's been in production since Firefly. In general it's been working well. Of course we've hit our share of issues, but it's been solid as a whole.
This post is about one specific hard to debug issue. Storage problems are sometimes notoriously difficult to pin down, and this was no exception.
Here's a list of keywords for search engines and your ctrl-f. Ceph slow writes, stalled writes, random performance drops, occasional stalls, few minute write stall
Symptoms
The symptoms of this problem were annoying to say the least, but hard to reproduce. I'm still not sure we're completely rid of them, but is has looked better for the last months.
Occasionally, the Ceph cluster would stall for sometimes a minute, sometimes 3, sometimes 5. It could happen once, or twice/three times in a row. It was clearly visible in the our graphs, and clearly seen on the customer side, but it was never long enough to properly debug, and left very little log trace.
The problem appeared once every few weeks, sometimes once or twice a week. It was random enough and short enough that it was really hard to debug. I think we have had this problem for a longer time, but because it has sometimes been even months between any issues, it's hard to tell.
We have decent monitoring using these excellent collectd modules. Using these we found that our cluster throughput just tanked. Basically no data in, no data out. The radosbench is run every minute to check latencies. These were usually missing when we had the issue, so not even radosbench got an answer. So at least it wasn't a problem with a specific pool.
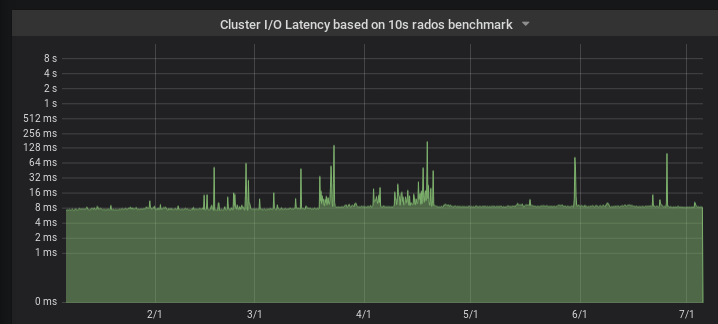
Sadly the data has already been aggregated, and the granularity reduced, so I can't show the exact graphs, but here at least you see the more active period of the problem from February to May (and a few operator whoopsies after that). The latency peaks correlate with the missing latency reports which aren't visible in this granuarity.
On the client side, the Qemu logs were basically of just as little help as the Ceph logs. There were some timeouts with OSD connections, which I guess is normal if the cluster isn't answering. The connection timeouts were also spread out across OSDs, and didn't match up with specific OSDs or servers, no matter how much I wanted to see patterns to have something to blame.
Fixes?
We tried a lot of different things to fix this. Restart OSDs with high commit latencies (which are also visible in Grafana, it's great). Take some suspected possibly bad nodes offline. Make sure there is no network interference. Update Ceph. Tweak Ceph client/server configs. Turn off deep scrubbing. Turn on deep scrubbing. Turn off deep scrubbing again. This all took place over months while debugging efforts continued.
At some point we looked at our virtualized MON nodes. We saw the load rise on them occasionally, and some of the higher loads coincided with the slowdowns. Looking at it later, I think we saw patterns where there were none, there were also just as high loads without any problems.
Either way, based on the data we threw some more CPU and memory at the MON VMs, and rebooted them. I would like to say Boom! It got fixed. Due the random rare pattern of the problem it was more like
We haven't seen this problems in now three weeks. I think we did the monitor node fix around that time. Maybe it helped?
I'm also not sure if it was the additional resources that helped, or simply rebooting the nodes after a long uptime.
Now?
We've had a few months now without this exact problem. So I think it might be fixed. It might come back after a long monitor node uptime, or it might be gone forever. Most likely we'll see the same symptoms at some point, and think it's the same case, while it might be something else.
The best case is that someone as desperate as I reads this blog post, reboots their MON nodes and solves the issue in a a week instead of months (and sends me a beer over the internet).
Geek. Product Owner @CSCfi
