Agile Services - Part 3: The Work We Do

This is the third post in the series about how to apply Agile methods to run services based on existing software.
The first post describing the problem at some length is here, but the TL;DR; is
I don't think there are great resources on how to apply agile methods to run and develop services based on existing (open source) software. We have struggled with it, and I try to write down practices that work for us, mostly taken from Scrum and SRE.
The second post discussed how the service lifecycle looks and when, what kind, and how much work we need to apply to the service.
I promised to discuss about how we work, but after thinking about the topic, I decided to split it into two posts. I'll start with a post what we work on first. It may sound like the answer is obvious, we know our work right? However, I think doing a deeper dive helps us organize our work.
This blog post concentrates on the work in production services (Horizon 1).
Normal disclaimer: these are my own opinions based on my own experiences.
The Phoenix Project: When Literary Sources are Fun!
Stig Telfer, who has been working with scientific OpenStack services for ages, and really knows the work, made a good comment on the first post in this series. He asked what my opinion was on the book "The Phoenix Project"?

I did read it a long time ago, and after the comment I decided to re-read it. For those of you who haven't read it, I warmly recommend the book. It's an IT thriller that takes you step by step - almost sneakily - through a lot of best practices in IT operations (although for the work/life balance not so much). I love the book, and also its textbook sibling, Lean Enterprise. Although they start to be old, they are still very relevant. I originally read about the service horizons - which were discussed in the last post - from the Lean Enterprise book.
How to Classify Work
The Phoenix Project also discusses categorizing work. It talked about four types of work, Business Projects, Internal Projects, Operational Changes, and Unplanned Work. While it's a start, I don't think this categorization does a great job of helping us organize and schedule work.
In this post we'll discuss the work we do, but I scope it to the work admins generally do. So e.g. financial planning and marketing is out of scope, even though they are important for a service.
I must admit, I only have partial and scattered literature references for this work categorization. Half of this is based on experience, and the main point is focus on the abstraction level that makes sense on a service and team level. Although this on many levels analogous to different chapters of the Site Reliability Engineering (SRE) book.
Let's Start Rough

I will use this kind of chart throughout the blog. In general, the priority of the work goes from the bottom to the top, the value of the work goes the other way. We'll get to this later.
On the very high level, we have two types of work. Unplanned and Planned. While e.g. The Phoenix Project specifies unplanned work as disaster/incident management. I think that the scope and impact of unplanned work is much wider. So, I'll go with the definition
Unplanned work is work that interrupts an admin, and may have to be scheduled as a higher priority than current tasks.
Planned work is work that does not come as a surprise, and can be planned for. An important note is, that planned work does not become unplanned work if you don't plan and schedule it. It just becomes poorly planned work under time pressure.
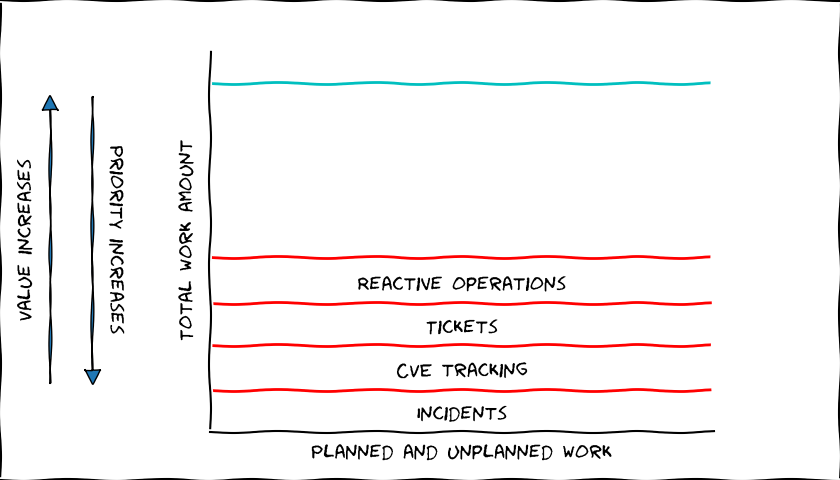
Unplanned Work
Unplanned work is mostly unwanted work. This is interrupting and reactive work that spoils our concentration, and draws our focus.
Unplanned work can itself be split into different types of tasks. I'll go through them from highest priority to lowest. The categorization may vary a bit, but I think this gives the general picture.
Incidents / Disasters
You get a call in the early hours of the morning that your service is down. You either open up the laptop or quickly jump in the car, and call all hands on deck to deal with this problem. With any luck you have communication and incident handling planned so you know how to tackle the problem. Either way, you know that any plans you had for the day are shot, and you just hope they fixed the coffee machine. You let out a big sigh start gathering a situational view.
I'm sure most IT admins have had a day like this, and I doubt many have enjoyed it. This is the most disruptive and costly work we can have. Not only usually take away everybody's time to manage the incident, but it also affects the customers.
You can't avoid having any incidents, but you can do a lot to reduce both the likelihood and the impact of them.
CVEs, Security Tracking
Then we get to the less stressful, but still interrupting work.
We should track the relevant CVEs for your system. These come unexpectedly, and we have to evaluate our response to them. While handling these is relatively time critical, it doesn't require all hands on deck.
Still, these are interrupting tasks that may have a very high priority.
Customer Tickets
Depending on how our work is organized, we get varying amount of customer tickets. These usually have some expectation of urgency, and we can't plan for these. We can of course reduce ticket amounts, with e.g. documentation.
Reactive Operations
Regardless of how we run our service, we have some infrastructure we have to manage, whether it's hardware, virtual machines or containers. These have problems that need to be worked on. Our monitoring will hopefully detect these and alert on these. If we have a proper redundant setup, these are not very time critical, but not addressing these will cause the service to slowly rot.
A large part of this work is also to debug different problems that pop up, which may have been caused by anything from changes in upstream software to scaling issues when your service grows.
A simple hardware example would be that a hard disk is failing and needs replacing. If we work on a higher level of abstraction, this may be that our monitoring alerts us that one of our containers can't start, and we're running on reduced redundancy.
Summary of Unplanned Work
Unplanned work needs priority and usually has some reaction time requirements. The worst thing about unplanned work is that it is critical for our service, but it brings no real visible value. If this work is ignored, our incident amounts grow, which is very expensive, demotivating, tiring, and annoys the customers.
If we take a flashback to the first blog post in the series, this unplanned work is one of the main reasons I think pure Scrum doesn't work in this environment. Unplanned work is basically ignored by Scrum, and Scrum doesn't provide good tools or processes to manage this work.
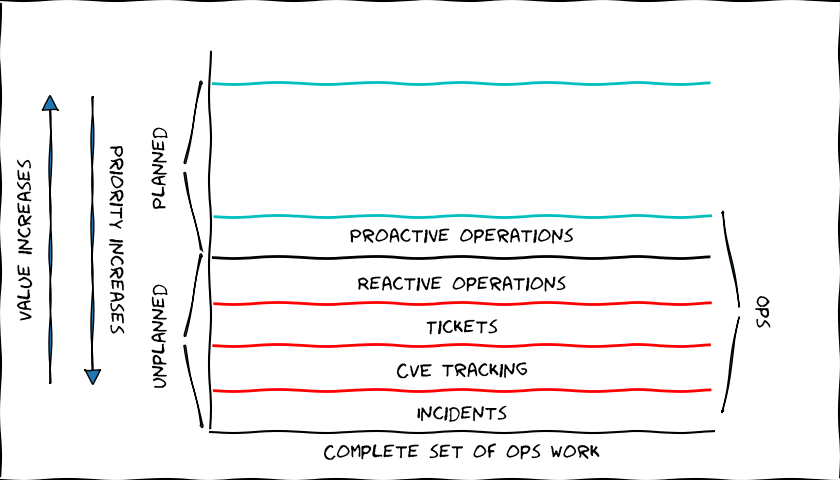
Planned Work - the not-so-fun part
In addition to reactive work we have another type of work which generates very little value, but can be planned for.
Proactive Operations
Some operations can (and should) be planned. Examples include periodic updates and service certificate renewals. Much of the work in your annual clock for e.g. compliance work would also fall under this category. Other examples can be bug fixes for parts of our service that doesn't work as expected.
This operations work, like the unplanned work, does not bring much visible value, but it keeps the service running.
Meet Ops, Made Famous by DevOps
All the things we have so far mentioned, incidents, CVEs, tickets, and proactive and reactive operations make up the "Ops" part of DevOps in our context.
There are a few very important points that these things have in common
- These tasks don't improve our service, they only help us not slide backward.
- These amount of tasks tend to scale linearly with your service, often based on customer amounts or the scale of the service.
In the previous post, there was a sharp increase of work when a service enters Horizon 1. The reason for this is in large part the ops work, especially if our service scales up.
While from one point, this work feels useless (SRE calls it "toil"), this is still the most critical work to do to keep our service stable. If this work is ignored, or not prioritized, out service starts to "rot". This leads to the service always being in a broken state, monitoring is probably flagging (which we ignore, as it's been there for a while), and we get a backlog of broken issues that will affect the service in a myriad of ways. There is some leeway on how thorough we are in our ops work, but it's easy to underestimate the work, and to not do it properly.
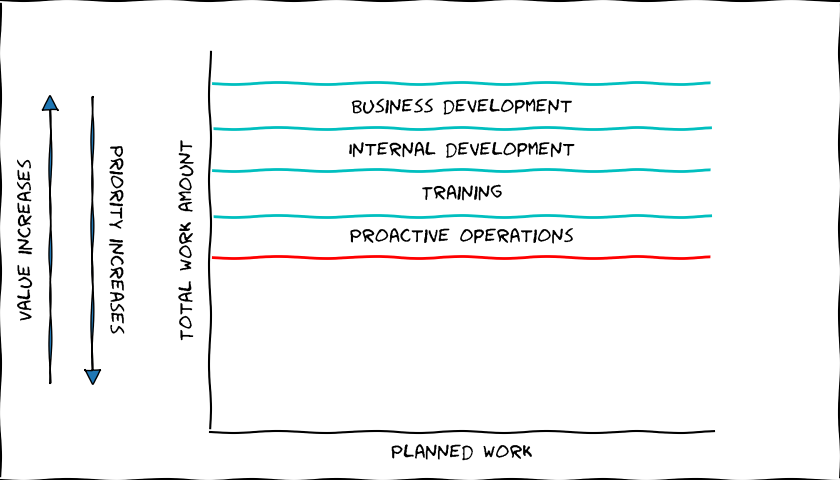
Planned work - the valuable part
Now we get to the more valuable work. Again, let's proceed in approximate priority order. The prioritization of planned work depends a lot on our teams, internal needs, business needs, and scale but I think this general prioritization a reasonable starting point.
Learning and Training
I have yet to meet somebody who has complete knowledge of their domain. This also goes for admin work. There is a need to constantly learn and improve. The amount to learn depends on the complexity of our service, but learning is never ending. Things change, we need to focus on different aspects of the service, and new technology comes in. A lot of our learning happens by actually doing work, but not all of it.
Then we inevitably have people who join the team, either because you grow, or because somebody left to pursue other interests. Making new people productive won't happen magically without work. It takes time and effort to get someone up to date, especially if we are working with complex systems.
This work is an investment, that takes a whille to repay itself. It not only makes sure we work more efficiently, but it is also great for reducing business risk. The wider knowledge each admin has, the less impact it has when people inevitably leave.
Internal Development
Internal development is a big mix of work (and, mentioned specifically in The Phoenix Project). This work comprises everything that needs to be developed, but the need comes from inside our team (or, very close by).
Internal development usually aims at one of the following
- Improve tools/processes/monitoring/documentation to reduce operations work (automating/standardizing/etc.)
- Make sure software/components are up to date, which reduces risk, and by that operations work.
- Do internal development work to enable future business development of the service (e.g. architecture updates).
Reducing the ops work (either directly, or indirectly) is a major factor in most internal development tasks. Any resources you can free up from ops work goes directly towards development, perpetually. This means, you can do one time investments, that - like training - have significant pay offs in the long term.
However, at some point there will be diminishing returns when the lower hanging fruit have been picked. Further automation may only be cost-efficient if the scale of the service grows.
Business Needs
Reacting to business needs takes development effort. This work usually is the most directly impactful, and the most important work we do. However, this work almost always also increases service complexity and long term operations work.
To be able to do development, we have to have the underlying service in shape, i.e. control of our incidents and operations, and having up-to-date admin skills. Otherwise we risk ending in a technical debt spiral.
Tangent on Technical Debt
Unsurprisingly, developing for business needs can be a major source of technical debt. It is deceptively easy to create technical debt, and technical debt has characteristics in common with financial debt. The more debt we take, the more expensive the interest payments are, and the less new debt we can afford.
Technical debt is often accrued by taking shortcuts. E.g. we do an upgrade of a component, and we would need to upgrade the monitoring, as the update broke the current monitoring. Or we install a new feature, but decide to add monitoring and documentation later. That work is is postponed, because of new important development work. Now we're in a situation where our operations work is harder, which slows down further development. However, we did finish the original task faster, and can work on something else.
Sometimes the source of technical debt comes from implementing things without considering the wider effects. The further in the future we look when making development decisions, the less risk we have of creating technical debt.
I would also include another type of work into the concept of technical debt. If we don't do enough internal development work, we can't react to changes in the environment. We can be behind in e.g. software updates, process implementations, or service integrations. This means we have a large backlog of internal development, which needs to be prioritized, and increases our technical debt.
Taking some technical debt is not necessarily always bad. Sometimes it's worth taking technical debt in favor of speed. However, taking technical debt should always be a conscious decision, and we should understand the impact and cost of taking the extra debt. We also need to make sure we can pay it off. The interest payments are usually in ops.
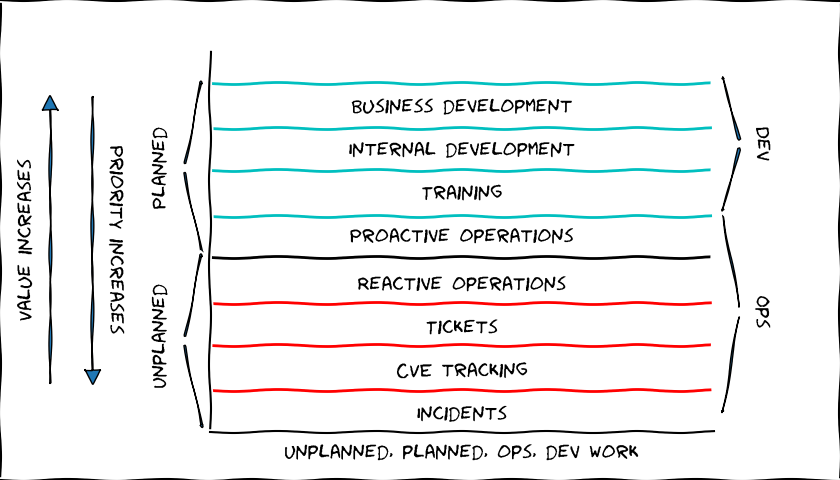
Say Hello to Dev
Working on internal and business needs is dev work. It usually requires code or process development. Dev work has an excellent property, that the work amount rarely scales with the service size. We want to spend as much time as possible doing dev work, which ironically means we have to prioritize ops work.
Dev work is partly covered by the SRE book, but it mainly focuses on the internal development work. In SRE the business needs mainly fall to a separate dev team. If you're responsible for a service based on existing software, the admin team needs to react to the business development needs too. This is a large chunk of work, and puts more requirements on the team.
The design decisions we do while working on dev work can have an enormous impact on our ops work. This is not only because of shortcuts where we accumulate technical debt, but our design decisions have a huge impact on future operations work.
Doing development work has two chances for payoff. First, the immediate benefits when the work is done. This is often obvious.
The second possible payoff sometimes comes with a delay of a year or more. If we have done the work properly, we can mitigate much long term extra ops work, and the internal development work we need to fix it. The possible future work can easily exceed the development effort.
Balance
Are there any guidelines how much of the work should be ops and how much should be dev for a service?
I had been struggling with this question for a while while thinking about the workload of our teams. This also links to the previous post, where I stated that every Horizon 1 service needs some amount of development, or it's in practice a Horizon 0 service.
Then I happened to re-read the SRE book for background material to this blog series, and right at the beginning, in the first chapter of the book, I found this gem that I had forgotten
Therefore, Google places a 50% cap on the aggregate "ops" works for all SREs - tickets, on-call, manual tasks, etc.
Now, in our context the admin role is wider than what the SRE practices describe. SRE work concentrates on supporting services developed by a separate development team. In our case, we're doing some of that development work ourselves, so the 50% limit may even be too low!
In practice, this 50% is of course not set in stone, and the suitable level depends on a lot of factors; the complexity of the service, the speed of upstream development, the changes in business needs, the team running the service, the lifecycle stage of the service, etc.. I guess that every service has an approximate suitable ops/dev split. If you have more ops than that, you will start falling behind and accumulate technical debt. If you have less ops, you can catch up and pay off debt, develop more, or extend the responsibilities of the team. 50% sounds like a good starting point though.

Next up
Now I can with some certainty say, that the next blog post will be about how we actually practically organize this work. At least I hope I won't get sidetracked by another interesting aspect of the problem, and write about that instead. (Edit: I partially succeeded.)
Geek. Product Owner @CSCfi
