Logical Volume Management
Or: Paying the Price for Technical Debt

We have run OpenStack for a while. I think we went into production around Grizzly. Back then we were new to running production OpenStack systems (who wasn't?). This means we made some decisions back then, which we are still paying for.
Credit where credit is due: Almost all the real work described in this post was done by my colleagues, @carloscar for the technical part, and @junousi for customer management. I'm just writing this up.
Disclaimer: The work in this blog post was done on OpenStack Liberty and Ceph Hammer.
Hindsight 20/20
This time, I'm specifically talking about storage, which - in my opinion - is especially bad for technical debt. This is where we tell our users to put the state of their systems. This means that any storage decisions have very long term effects.
Back in 2013 we decided to use LVM + iSCSI for our Cinder storage backend. We used pretty much a standard OpenStack setup for that at the time. The storage backend was a DDN SFA system which was shared with our HPC system. We did have the questionable foresight to double up on our storage servers, so we could be "HA". Here you see our original architecture.
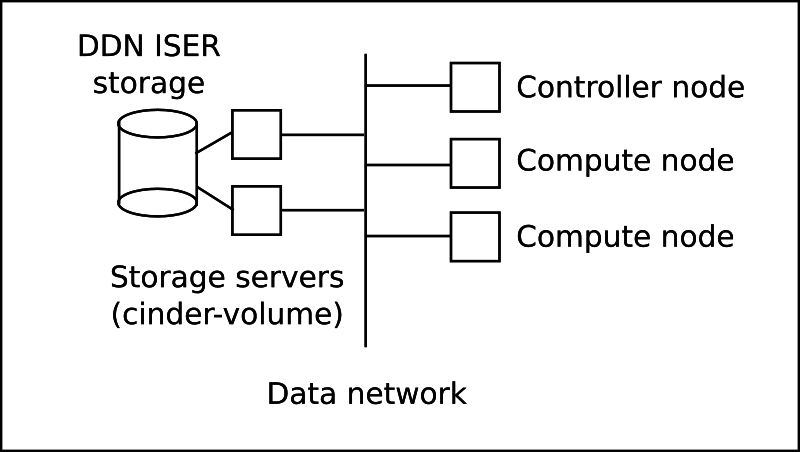
(My next job will be in graphical design)
This solution uses just plain iSCSI towards OpenStack, no multipath. Our plan was that, if needed, we can fail over all the storage to one node and service the other. Towards the DDN side we used ISER with multipath, and both storage servers could - if needed - mount all the storage.
The lesson we learned after running OpenStack for a while, was to always have a maintenance, an upgrade, and preferably an exit plan for any new features you bring in. Well, our LVM based Cinder had half an idea of a maintenance plan. If we need to maintain the servers, we can always switch all the storage to be served from the other server, right? In practice, it was never tested.
Once in production it was impossible to test the plan, and to actually make it work. Even if we somehow succeeded in this, we'd cause customer-facing outages with every maintenance break by cutting their iSCSI connections.
We had ended up with two servers which exhibited strong single point of failure characteristics. They were hard to maintain, impossible to do operating system upgrades on, and required a separate well tested plan when it came to OpenStack upgrades. If our team ever writes a manual on technical debt, the picture of these servers will be on the cover.
Don't get me wrong, we got them into quite a nice stable working order. From the customer point of view they worked quite well after some early pains. However, they had to go.
The Pain of Separation
We already had a replacement system for this. We had deployed our Ceph based Cinder volumes a while back. Naturally there had been some early issues when we were learning to manage Ceph, but we got it into a state where we could trust it.
Now all we had to do was move all the data from an old iSCSI/LVM based system to Ceph in a way where OpenStack doesn't get confused. All this should preferably be transparent to the end-user.
Typing Away
I was positively surprised to find Openstack actually has a tool to help us here. If you have a new enough version of the Cinder CLI, you'll be able to type
cinder retype <volume> <volume-type>
This pretty much does exactly what we want. The cinder-volume service of the source volume type does most of the work.
- A volume of the new storage type is created . It's hidden from the user.
- The volume is shown to the source cinder-volume server.
- Cinder-volume copies the data from the old volume to the new one (the method depends on the volume type).
- The old volume is deleted.
- The new volumes UUID is set to match the old volume.
- The new volume is made visible to the user.
There are some restrictions though
- The source volume can't be attached
- The source volume can't have snapshots
- The source volume can't be bootable
The restrictions ruled out about half of the volumes. Even with them, the command helped us a lot.
Cinder retype is not optimal, since it copies the whole content of the volume to the new backend. So a 10 TB LVM based volume, which actually has 500GB of data will consume 10 TB of Ceph space. Most of that will be zeroes. The cost of the extra storage is still probably much cheaper than the cost of the extra admin work to do transfers manually.
We were happy to see that the whole retype operation seemed to handle error situations quite well too. If something failed, the original volume either stayed in the "migrating" state or went to an "error" state, both of which were completely recoverable. Sometimes you also had to clean up the new volume, if the retypes failed. We never encountered a problem which would lose data.
We did hit a few issues on the way.
Just OpenStack things
If cinder-volume crashes, or if it's restarted, you lose all retypes which are in progress. This also puts the customer volume in the "ERROR" state. Admins can easily recover the volume from this state, but end-uses can not. So keep track of the volumes that are being retyped, both by you, and by customers.
There was another interesting bug (since fixed) we encounter while trying to be helpful admins. When Cinder created the new target volume, it marked off the the quota-usage from the project that did the request - in this case the admin project. When the retype finished, it released the quota-usage to the target project. This means that there were some interesting quota errors when doing the retype.
Buggy Ceph Clients
We had a problem with cinder-volume not closing file descriptors after a retype. This turned out to a Ceph client issue, but of course we didn't catch this in testing. This meant that in production our cinder-volume ran out of file descriptors and went into a bad state and we had to debug. Our fix was restarting cinder-volume after a few retypes. While not a pretty fix,it seemed to be Good Enough (TM) for this.
Running out of Space
I warmly recommend Grafana for your Ceph data. It looks cool,it's easy to push data there, and it's... easy to misinterpret it.
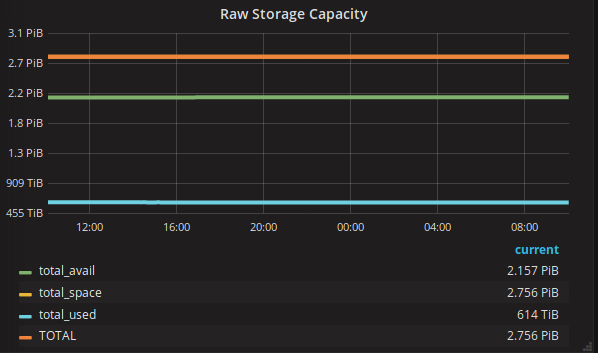
We track the available space we have left on Ceph. Moving all the data from the old storage to Ceph ate quite a large chunk of the free space, but our graphs showed that there was plenty of free space. What we didn't consider was that not all Ceph OSD nodes were used by all pools. So our Cinder pool filled up without us noticing, which meant no more writes were accepted. This meant a bit of a crisis, and some scrambling to fix this, especially since it took a while to find the cause.
We got it fixed, and long story short, we now look at per-pool capacity in Grafana.
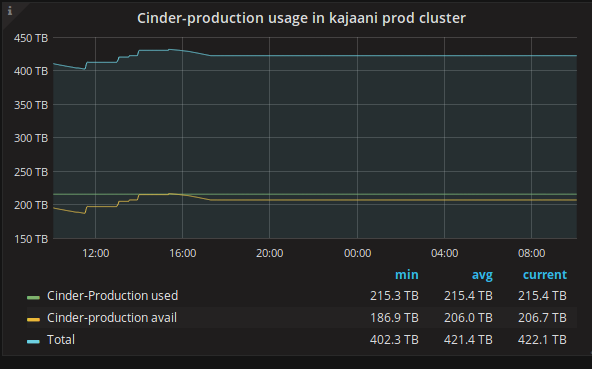
Then What?
After the migration process was a bit more fine tuned, it actually worked like a charm. We gave our customers a deadline when the old storage is deprecated. Then we opportunistically migrated all the volumes we could. We sent more warning mails to customers saying they should move the data. Some listened, some didn't. When the deadline approached, our charming customer support person/admin, Jukka, did tons of legwork, and contacted the remaining customers, planned their exit from the old storage, and implemented it.
This whole migration from the old storage system was a lot of work, but we got the old system emptied, and we didn't lose any data we shouldn't have. As a whole, it was a great success.
Debt Repayment
When you finish a batch of work like this, it feels like paying the last mortgage payment on your house. Sure, you still have a car loan and credit card debt, but now there's some more wiggle-room for paying those off.
TL;DR;
When you add hardware/services to your cloud, plan how to maintain them and how to get rid of them. Otherwise you have to do a lot of work.
Geek. Product Owner @CSCfi
